 Artificial Intelligence
Artificial Intelligence
Self-driving cars: AI’s big bet
The car has had a remarkable impact on human history in the past 170 years since the first four wheelers hit the roads. From a mechanical challenger to the established means of transport at the turn of the 20th century to its dominant status throughout the 20th century as the core means of land transport for individuals and commercial uses. The car has experienced a wide spectrum of public attention statuses over the past 100 years or so: an iconic symbol of someone’s wealth, ownership elevates the owner to a higher societal status; a villain responsible for the outrageous pollution caused all over the world by intense car usage, the main reason for our clogged-up journeys to work and leisure; a culprit responsible for the 1.3 million deaths caused by car accidents every year and another 30 million injured. But somehow, our relationship with cars remains undented: there are well over 1.2 billion cars on the roads today, and some estimate that there will be over 2 billion by 2030.
However, one field of technology that captured the imagination and awe of practitioners with its recent meteoric progress and impact on society, artificial intelligence, aims to change our relationship with cars by altering their fundamental principle: from machines driven by humans to machines that are self-driven, rendering humans to mere passengers. That’s a lofty goal, and somehow controversial, but it has merits, advantages and disadvantages.
But first let’s unravel the notion of self-driving and see what it means and what stages it involves before a car become fully autonomous. The society of automotive engineers (SOE) has proposed a taxonomy and definitions for autonomy levels of cars’ automation systems, and national bodies such as the office of science and technology at the UK government below slightly adapt them:
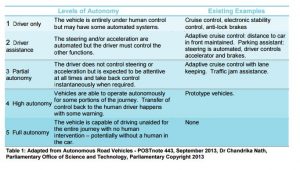
Clearly level 5 hasn’t been achieved yet for large scale commercial use. Level 4 is where most of the action is today. But, we already have automation systems in our cars that continuously evolve: assisted driving functions such as satellite navigation and cruise control are now well-known, and anti-lock braking systems (ABS) – to automatically activate safety mechanisms – have been mandatory on new passenger cars in some regions. Modern cars contain tens of electronic control units (ECUs), computers which control everything from a car’s engine to onboard entertainment systems. “Drive-by-wire” technology, which replaces traditionally mechanical connections with electrical systems (analogous to aviation’s “fly-by-wire”), has also become increasingly common. In fact, many drivers today are unaware of just how automated their vehicles are.
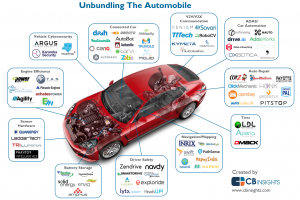
So where does AI fit in the quest to achieve L4 and L5 autonomy levels? AI has been there for a long time; since the 1960s at least with a focus on computer based guidance systems for the aspiring self-driving cars. Main aspects of the early efforts were to reverse engineer car navigation to a powerful combination of three elements: sensing, processing the outside world signals and make decisions as per next move, and reacting to changes in the environment and if necessary, make appropriate moves (e.g., crash avoidance, emergency stops, manoeuvring). It appears that the most challenging bit is the processing of outside world signals as it is the “understanding” of car’s surrounding environment – the other two steps use conventional technology from radars and laser sensors to mechanical parts administering movement. The AI progress was incremental, rather than revolutionary. In the 1980s E.Dickman’s Mercedes van drove hundreds of motorway miles autonomously, and by 2004 a US DARPA challenge in a desert setting brought many self-driving cars to compete with each other. That pivotal moment, brought many of the breakthroughs we see today. We now have better AI software for road-following and collision avoidance, improved radar and laser sensors, and comprehensive digital mapping technology. And the results are impressive in technology and performance terms for self-driving cars. NVidia’s machine learning algorithms, for example, enable continuous learning and safe updates of a car’s learning algorithms, even in the field. A large number of manufacturers are involved too, with more than 30 global corporations working on AI projects to build fully autonomous cars; and peripherals’ suppliers such as Bosch that works on the radar and other sensors used. Google’s self-driving cars have driven millions of miles to fine tune their algorithms and Uber’s self-driving cars follow a similar journey. This flurry of activity is evident in the emerging ecosystem of self-driving and autonomous cars “unbundling the car” trend, as market intelligence outfit CBInsights put it: “[they] are working not only in self-driving tech and automated driver assistance but also to improve different services and products associated with the auto industry. These range from high-profile autonomous driving startups like comma.ai, backed by Andreessen Horowitz, to companies focused on enhancing more traditional elements, like auto repair and tire technology.”
But we shouldn’t get too excited, yet. There are a lot of obstacles to overcome in order to achieve the fully autonomous, L5, self-driving cars we’re dreaming of. And the reasons are not only current technology limitations.
Legal considerations
It’s easy to imagine bizarre situations when the driver of a car, is not really driving the car – as the car is self-driven – but instead she is physically present, and the car is involved in an accident or other activity that has legal implications. Questions such as who’s at fault when things go wrong, liability for insurance, 3rd party suppliers’ involvement (from road sensors manufacturers and fetch data to the autonomous car to machine vision suppliers that enable the car to “see”), and other need clarifications. At present in the UK at least, primary liability rests with the user of the car, regardless of whether their actions cause the accident or not. If defective technology caused the accident, the user (or their insurer) has to pursue this legally with the manufacturer. In addition, at present drivers are expected to maintain awareness and supervision of their car, even if they are not in control of driving because semi-autonomous features are engaged, for example both Lane Keeping Assist or cruise control. However, this is not as clear cut as it sounds. If we look at L2 automation features, such as (adaptive) cruise control, there is an interesting case in the States with inappropriate use of cruise control: Mrs Merv Grazinski of Oklahoma, sued successfully the manufacturer of her new motorhome after she crashed it at 70mph while making a sandwich! Apparently, she put the motorhome on cruise control and left the steering and driver seat to go and make herself a sandwich. She argued that the manufacturer failed to inform her not to leave the steering when she set it on cruise control. Textbook guidance on cruise control tell us that when used incorrectly could lead to accidents due to several factors, such as: speeding around curves that require slowing down, rough or loose terrain that could negatively affect the cruise control controls and rainy or wet weather could lose traction.
So, in situations like this it appears that inappropriate interpretation of how to use an automation feature is the reason to put liability on the human driver, as they should maintain control of the car at all times. But that’s quickly becoming counterintuitive and blurry when you drive a “self-driven” car, which subconsciously raises the expectations that the car will drive by itself. The analogy of autopilots in aircraft is interesting: autopilots do not replace human pilots, but assist them in controlling the aircraft, allowing them to focus on broader aspects of operation, such as monitoring the trajectory, weather and systems.
It seems that the race to develop L5 autonomy level cars has outpaced the current legislation. When L5 is fully developed, for example, human drivers (or rather users) could be legally permitted to be distracted from driving to do things like send text messages. But this could require fundamental changes to legislation. Further, if laws are changed such that they no longer require any supervision in cars, a change in liability assignment may also be called for to reflect the fact that car drivers/users are not expected to have any control over or awareness of the driving. And to make things even more complicated, issues arising from different country-level, region-level and global legislation for behaviour of car users need to be reconciled. Manufactures of L5 cars might be required to adhere to data management standards for downloading software update patches to autonomous cars whilst in different territories and maybe in network outage areas, and so on. Also, licensing procedures could be affected, as the role of a driver changes to that of a trained user of an autonomous system, something akin to the rigorous training aircraft pilots undergo in order to operate complex autopilot systems.
Moral and ethical dilemmas
Even we find a way to come up with sensible and practical legislation that recognizes the new role of (human) drivers, we still have to grapple with moral and ethical dilemmas. As cars become more autonomous, and have full control, they will be called to act in situations involving inevitable fatalities. An interesting virtual test set up by researchers, is trying to gauge public opinion on what a self-driving car should do in such tricky situations. This moral robo-car test shows that people are in favour of utilitarianism and go for the situations where less human lives are sacrificed. But their feelings are shifting when they are the ones who might be making the sacrifice.
Ethical issues regarding programming for self-driving cars affects the manufacturers. In the absence of legislation, manufacturers will have discretion to make certain ethical decisions regarding the programming of their cars, and consumers will be able to influence programming based on their purchasing preferences. This is going to be tricky, to say the least. Apparently, the survey from the moral robo-car site revealed that people are less likely to buy self-driving cars which have been ethically programmed to act in certain ways. It could then be the case that due to low demand of this type of cars, manufacturers will not make them, which could reduce the overall benefit of self-driving cars.
Tackling moral and ethical dilemmas a priori is difficult. When we learn to drive, we don’t have a predefined, morally acceptable list of outcomes when we faced with such situations. If we are unfortunate to experience one, we act on the spot following our instinct, emotional state at the time, influenced by factors such as adrenaline, and other biological (over-) reactions which are tricky, if not, impossible to interpret, codify and load onto a self-driving car’s memory.
Insurance implications
Car insurance will almost certainly change completely from what we know today, if and when L5 self-driving cars hit the roads. A drastic reduction to car accidents will necessitate the re-thinking of having an insurance in the first place: as human’s affect the risk calculation and drive up or down the premiums. For example, KPMG predicts that car accidents will go down by 80% by 2040 thanks to self-driving cars. However, regardless of who is controlling the car, humans will continue to be present in, or have supervision of, autonomous and unmanned cars. Training and education will be required to ensure that people who interact with these vehicles have the appropriate competence and awareness to ensure safe and responsible operation.
Implications can be drastic for the insurance industry as whole: there could be no claims processors and loss adjustment, but still there will be a need for some sort of insurance (possibly covering theft, vandalism, etc.) Insurance of L5 cars could well be linked to software industry practices and reward, or otherwise, good software updates practice, driving habits (as they will be all monitored with advanced telematics) and other technology related features.
Also, switching between fully and semi-autonomous driving should also be considered in insurance context. There is a risk that a driver could misjudge the responsibility they currently have, or may not adequately understand how to choose different modes of operation of their car or even how to retake control of the car when it is necessary. This may be a more difficult risk to address than it seems – anecdotal evidence suggests that people tend to ‘switch off’ when it seems that their input is not needed.
AI technology is not enough
The challenges listed above are difficult to tackle. At the same time, we push forward with advanced AI techniques making serious inroads toward L5 self-driving cars. It appears that we need to pace our technology progress with progress on all other fronts; legal, moral and process (insurance, infrastructure, etc.). And progress on the other fronts will mean getting that knowledge into our AI-driven cars, thus making a truly intelligent and complex AI to drive flawlessly our L5 self-driving cars.
But, as we strive to get there, we need to be more open and transparent about what works, and what doesn’t. Commercial interests, technological excitement, and heighten expectations at times make us forget that we shouldn’t rush the journey. Getting L5 self-driven cars out there is not a panacea. Some believe is not even necessary. As older cars are not likely to be retrofitted to keep up with their L5 modern siblings, there are also people who enjoy driving in itself – for example, it is estimated that there are more than half a million classic cars in the UK. And a study conducted by the UK’s Automobile Association found that 65% of people liked driving too much to want an autonomous car. AI’s bet on delivering the core technology that will make, eventually, L5 self-driving car is indeed a big one. Possibly one of its biggest thus far.

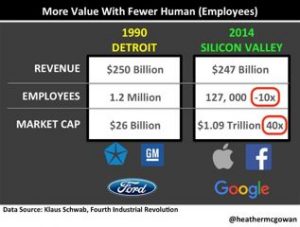
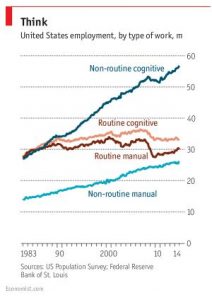




{kind=link}